6 Working with Data in the Tidyverse
https://learn.datacamp.com/courses/working-with-data-in-the-tidyverse
6.1 Explore your data
Import Data -
Rectangular Data : Columns represent variables while rows represent observations. The readr package is for reading rectangular package into r.
?read_csv arguements:
file : Either a path to a file, a connection, or literal data (either single string or a raw vector).
To change the name of a file we are importing, we use : bakers <- read_csv(“bakers.csv”)
## ── Attaching packages ───────────────────────── tidyverse 1.3.0 ──## ✓ ggplot2 3.3.3 ✓ dplyr 1.0.2
## ✓ tibble 3.0.3 ✓ stringr 1.4.0
## ✓ tidyr 1.1.2 ✓ forcats 0.5.0
## ✓ purrr 0.3.4## ── Conflicts ──────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()## # A tibble: 1,704 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779.
## 2 Afghanistan Asia 1957 30.3 9240934 821.
## 3 Afghanistan Asia 1962 32.0 10267083 853.
## 4 Afghanistan Asia 1967 34.0 11537966 836.
## 5 Afghanistan Asia 1972 36.1 13079460 740.
## 6 Afghanistan Asia 1977 38.4 14880372 786.
## 7 Afghanistan Asia 1982 39.9 12881816 978.
## 8 Afghanistan Asia 1987 40.8 13867957 852.
## 9 Afghanistan Asia 1992 41.7 16317921 649.
## 10 Afghanistan Asia 1997 41.8 22227415 635.
## # … with 1,694 more rowsThe read_csv() function also has an na argument, which allows you to specify value(s) that represent missing values in your data. The default values for the na argument are c("“,”NA“), so both are recoded as missing (NA) in R. When you read in data, you can add additional values like the string”UNKNOWN" to a vector of missing values using the c() function to combine multiple values into a single vector.
library(dplyr)
library(tidyverse)
bakeoff <- read_csv("https://assets.datacamp.com/production/repositories/1613/datasets/53cf6583aa659942b787897319a1ac053cbcfa5a/bakeoff.csv")## Parsed with column specification:
## cols(
## series = col_double(),
## episode = col_double(),
## baker = col_character(),
## signature = col_character(),
## technical = col_double(),
## showstopper = col_character(),
## result = col_character(),
## uk_airdate = col_date(format = ""),
## us_season = col_double(),
## us_airdate = col_date(format = "")
## )## # A tibble: 0 x 10
## # … with 10 variables: series <dbl>, episode <dbl>, baker <chr>,
## # signature <chr>, technical <dbl>, showstopper <chr>, result <chr>,
## # uk_airdate <date>, us_season <dbl>, us_airdate <date>#Edit to add list of missing values
# bakeoff <- read_csv("bakeoff.csv",
# skip = 1,
# na = c("", "NA", "UNKNOWN"))
#Filter rows where showstopper is NA
bakeoff %>%
filter(is.na(showstopper))## # A tibble: 21 x 10
## series episode baker signature technical showstopper result uk_airdate
## <dbl> <dbl> <chr> <chr> <dbl> <chr> <chr> <date>
## 1 1 1 Edd "Caramel… 1 <NA> IN 2010-08-17
## 2 1 1 Jasm… "Fresh M… NA <NA> IN 2010-08-17
## 3 1 6 Mira… "Lemon C… NA <NA> RUNNE… 2010-09-21
## 4 2 1 Ian "Apple a… 10 <NA> IN 2011-08-16
## 5 2 1 Jason "Lemon M… 6 <NA> IN 2011-08-16
## 6 2 1 Urva… "Cherry … 7 <NA> IN 2011-08-16
## 7 2 1 Yasm… "Cardamo… 5 <NA> IN 2011-08-16
## 8 2 1 Holly "Cherry … 1 <NA> SB 2011-08-16
## 9 2 2 Ben "Chorizo… 1 <NA> IN 2011-08-23
## 10 2 2 Ian "Stilton… 2 <NA> IN 2011-08-23
## # … with 11 more rows, and 2 more variables: us_season <dbl>, us_airdate <date>KNOW YOUR DATA -
We use the function glimpse(data name) from dplyr package / skim(from library skimr) to see summary and overview of each data sets.
| Name | Piped data |
| Number of rows | 302 |
| Number of columns | 10 |
| _______________________ | |
| Column type frequency: | |
| character | 4 |
| Date | 2 |
| numeric | 4 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| baker | 0 | 1 | 3 | 9 | 0 | 48 | 0 |
| signature | 1 | 1 | 10 | 125 | 0 | 300 | 0 |
| showstopper | 1 | 1 | 5 | 126 | 0 | 298 | 0 |
| result | 0 | 1 | 2 | 9 | 0 | 6 | 0 |
Variable type: Date
| skim_variable | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|
| uk_airdate | 0 | 1 | 2013-08-20 | 2016-10-26 | 2014-10-08 | 40 |
| us_airdate | 0 | 1 | 2014-12-28 | 2017-08-04 | 2015-11-08 | 35 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| series | 0 | 1 | 5.49 | 1.13 | 4 | 4 | 5 | 6 | 7 | ▇▇▁▇▇ |
| episode | 0 | 1 | 4.37 | 2.66 | 1 | 2 | 4 | 6 | 10 | ▇▆▅▃▂ |
| technical | 1 | 1 | 4.85 | 2.98 | 1 | 2 | 4 | 7 | 13 | ▇▅▅▂▁ |
| us_season | 0 | 1 | 2.49 | 1.13 | 1 | 1 | 2 | 3 | 4 | ▇▇▁▇▇ |
COUNT -
We can count the number of observations (rows) by using the count() function.
Count the number of rows by series and baker
6.2 Tame your data
Covert variable types in R = Type Casting.
CHANGING TYPES OF VARIABLE:
Character to numeric : parse_number(“36 years”) This parses it to a number. To parse an entire column, we use the following code:-
bakers_tame <- read_csv(file = "bakers.csv", col_types = cols(age = col_number()))Find format to parse uk_airdate parse_date(“17 August 2010”, format = “%d %B %Y”)
Edit to cast uk_airdate desserts <- read_csv(“desserts.csv”, col_types = cols( uk_airdate = col_date(format = “%d %B %Y”) ) )
Arrange by descending uk_airdate desserts %>% arrange(desc(uk_airdate))
A good workflow for parsing dates using readr is to, for example:
Use parse_date(“2012-14-08”, format = “%Y-%d-%m”) first, then Use col_date(format = “%Y-%d-%m”) within cols() as the col_types argument of read_csv().
Sometimes we’ll need to start with casting, then diagnose parsing problems using a new readr function called problems(). Using problems() on a result of read_csv() will show you the rows and columns where parsing error occurred, what the parser expected to find (for example, a number), and the actual value that caused the parsing error.
Recode Values:
We can uyse the recode() function to change the names of observation for each variables(columns).
employee <- c('John Doe','Peter Gynn','Jolie Hope')
salary <- c(21000, 23400, 26800)
startdate <- as.Date(c('2010-11-1','2008-3-25','2007-3-14'))
salary_roe <- c(500, 600, 300)
employ.data <- data.frame(employee, salary, startdate, salary_roe)
employ.data## employee salary startdate salary_roe
## 1 John Doe 21000 2010-11-01 500
## 2 Peter Gynn 23400 2008-03-25 600
## 3 Jolie Hope 26800 2007-03-14 300Remember that the arguments of recode() are the variable that you want to recode, and then an expression of the form old_value = new_value. recode() is most useful when used inside a mutate() to create a new variable or reassign the old one.
## employee n
## 1 John Doe 1
## 2 Jolie Hope 1
## 3 Peter Gynn 1If we want to change John Doe to Charlie Chaplin and Jolie Hope to NA, we use the following code:
employ.data %>% mutate(employee = recode(employee, "John Doe" = "Charlie Chaplin",
"Jolie Hope" = NA_character_))## employee salary startdate salary_roe
## 1 Charlie Chaplin 21000 2010-11-01 500
## 2 Peter Gynn 23400 2008-03-25 600
## 3 <NA> 26800 2007-03-14 300Select Variable:
We can select or deselect columns by using the following code :
## employee salary
## 1 John Doe 21000
## 2 Peter Gynn 23400
## 3 Jolie Hope 26800## employee startdate salary_roe
## 1 John Doe 2010-11-01 500
## 2 Peter Gynn 2008-03-25 600
## 3 Jolie Hope 2007-03-14 300The select() helpers are functions that you can use inside select() to allow you to select variables based on their names.
In this exercise, you’ll work with the ratings data, and you’ll use a new helper function called everything() which can be useful when reordering columns. Use ?everything to read more. You will learn more about using helper functions in the next lesson.
## startdate employee salary salary_roe
## 1 2010-11-01 John Doe 21000 500
## 2 2008-03-25 Peter Gynn 23400 600
## 3 2007-03-14 Jolie Hope 26800 300## startdate salary salary_roe
## 1 2010-11-01 21000 500
## 2 2008-03-25 23400 600
## 3 2007-03-14 26800 300Renaming Variables:
The first step to taming variable names is to use the janitor package. using the following code:
##
## Attaching package: 'janitor'## The following objects are masked from 'package:stats':
##
## chisq.test, fisher.test## Employee Salary Startdate SalaryRoe
## 1 John Doe 21000 2010-11-01 500
## 2 Peter Gynn 23400 2008-03-25 600
## 3 Jolie Hope 26800 2007-03-14 300We can rename the variables by using the following code :
new_name <- employ.data %>%
select(Monthly_Salary = ends_with("lary"),
everything(),
-ends_with("date"))
new_name## Monthly_Salary employee salary_roe
## 1 21000 John Doe 500
## 2 23400 Peter Gynn 600
## 3 26800 Jolie Hope 3006.3 Tidy your data
WE need to make sure that the data is tidy. Each column should have a separate variable and each observation should be a row.
gather() function:
We can use gather() to collapse multiple columns into two columns.
tidy_employ <- employ.data %>%
gather(key = "Monthly_salary", value = "salary_roe",
factor_key = TRUE, na.rm = TRUE)## Warning: attributes are not identical across measure variables;
## they will be dropped## Monthly_salary salary_roe
## 1 employee John Doe
## 2 employee Peter Gynn
## 3 employee Jolie Hope
## 4 salary 21000
## 5 salary 23400
## 6 salary 26800
## 7 startdate 14914
## 8 startdate 13963
## 9 startdate 13586## employee salary startdate salary_roe
## 1 John Doe 21000 2010-11-01 500
## 2 Peter Gynn 23400 2008-03-25 600
## 3 Jolie Hope 26800 2007-03-14 300## salary employee startdate salary_roe
## 1 21000 John Doe 2010-11-01 500
## 2 23400 Peter Gynn 2008-03-25 600
## 3 26800 Jolie Hope 2007-03-14 300separate() function:
We can use the separate() function to separate a column into 2.
employee_first_last <- c('John_Doe','Peter_Gynn','Jolie_Hope')
salary <- c(21000, 23400, 26800)
startdate <- as.Date(c('2010-11-1','2008-3-25','2007-3-14'))
salary_roe <- c(500, 600, 300)
employee.data <- data.frame(employee_first_last, salary, startdate, salary_roe)
tidy_employee <- employee.data %>% separate(employee_first_last, into = c("First Name", "Last Name"))
tidy_employee## First Name Last Name salary startdate salary_roe
## 1 John Doe 21000 2010-11-01 500
## 2 Peter Gynn 23400 2008-03-25 600
## 3 Jolie Hope 26800 2007-03-14 300The opposite of separate is unite() function to unite two coluimns.
## Name salary startdate salary_roe
## 1 John Doe 21000 2010-11-01 500
## 2 Peter Gynn 23400 2008-03-25 600
## 3 Jolie Hope 26800 2007-03-14 300spread() function :
We use the spread() function to spread columns to rowas when we see that there are multiple variables in a column.
6.4 Transform your data
Complex recoding with case_when() to use logicals like if_else.
If we want to add a “status” variable which shows the status of our employees based on their salary, we can use :
employee <- tidy_employee %>% mutate(status = case_when(
salary < 22000 ~ "Poor",
salary > 25000 ~ "Rich",
TRUE ~ "Middle Class"
))
employee## First Name Last Name salary startdate salary_roe status
## 1 John Doe 21000 2010-11-01 500 Poor
## 2 Peter Gynn 23400 2008-03-25 600 Middle Class
## 3 Jolie Hope 26800 2007-03-14 300 RichFactors:
We can turn certain variables into factors.
employee_factor <- employee %>%
mutate(status = as.factor(status))
# Examine levels
levels(employee$status)## NULL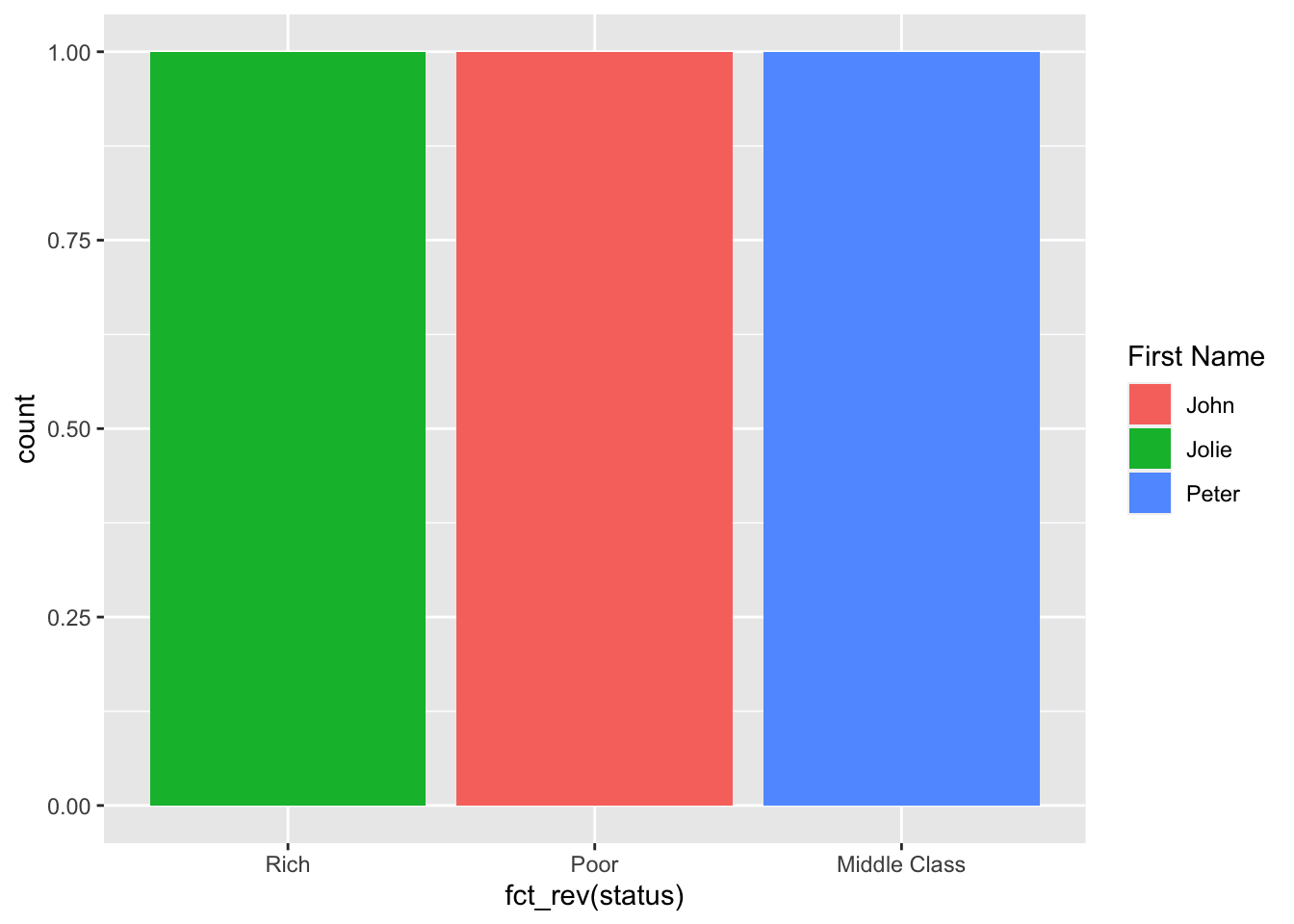
Strings:
We can do string wringling using the stringr package.
## First Name Last Name salary startdate salary_roe status Age
## 1 John Doe 21000 2010-11-01 500 Poor 24 Years
## 2 Peter Gynn 23400 2008-03-25 600 Middle Class 32 years
## 3 Jolie Hope 26800 2007-03-14 300 Rich 44 YearsWe can do string wringling using the stringr package.
We can separate the age variable into two columns. sep = “,” splits age and years into two columns. Then we use mutate() to change the type of the age variable to a numeric variable.
new_employee <- new_employee %>% separate(Age, into = c("Age", "Years?"), sep = ", ") %>%
mutate(Age = parse_number(Age))## Warning: Expected 2 pieces. Missing pieces filled with `NA` in 3 rows [1, 2, 3].## First Name Last Name salary startdate salary_roe status Age
## 1 John Doe 21000 2010-11-01 500 Poor 24
## 2 Peter Gynn 23400 2008-03-25 600 Middle Class 32
## 3 Jolie Hope 26800 2007-03-14 300 Rich 44We can use the stringr package to change strings to uppper case and lower case:
## First Name Last Name salary startdate salary_roe status Age
## 1 John Doe 21000 2010-11-01 500 POOR 24
## 2 Peter Gynn 23400 2008-03-25 600 MIDDLE CLASS 32
## 3 Jolie Hope 26800 2007-03-14 300 RICH 44We can use the stringr package to detect a specific string in a variable:
## First Name Last Name salary startdate salary_roe status Age Peter
## 1 John Doe 21000 2010-11-01 500 POOR 24 FALSE
## 2 Peter Gynn 23400 2008-03-25 600 MIDDLE CLASS 32 TRUE
## 3 Jolie Hope 26800 2007-03-14 300 RICH 44 FALSEWe can use the stringr package to detect a specific string in a variable and then replace it with another string:
new_employee <- new_employee %>% mutate(`First Name` = str_replace(`First Name`, "Peter", "Jonathan"))
new_employee## First Name Last Name salary startdate salary_roe status Age Peter
## 1 John Doe 21000 2010-11-01 500 POOR 24 FALSE
## 2 Jonathan Gynn 23400 2008-03-25 600 MIDDLE CLASS 32 TRUE
## 3 Jolie Hope 26800 2007-03-14 300 RICH 44 FALSEWe can use the stringr package to detect a specific string in a variable and then remove it.
new_employee <- new_employee %>% mutate(`First Name` = str_remove(`First Name`, "athan"))
new_employee## First Name Last Name salary startdate salary_roe status Age Peter
## 1 John Doe 21000 2010-11-01 500 POOR 24 FALSE
## 2 Jon Gynn 23400 2008-03-25 600 MIDDLE CLASS 32 TRUE
## 3 Jolie Hope 26800 2007-03-14 300 RICH 44 FALSE